Introduction
Recently, I had a conversation with someone on the Cisco Study Group Discord who was studying for their CCNP ENARSI exam. Great Discord if you want to join, by the way - lots of very insightful conversations! And of course, I’m there, so why aren’t you??? (If you are - say hi, why don’t ya!)
Thanks to Edmund B for the great question to write this post about! Anyway, they brought up how they were doing a lab to try to demonstrate EIGRP stuck in active (SIA) queries. Now, immediately, this made me raise my eyebrows…well, at least, as much as I could in my barely half-awake state at 7 AM. Why did I (try to) raise my eyebrows?
EIGRP SIA has traditionally been a very hard thing to properly lab, because, as you probably expect, SIA isn’t something that we run into just walking down the street on a Tuesday! Most ways of trying to lab SIA aren’t great, because there are a storm of conditions that need to be satisfied to reliably lab it:
- The router (let’s call it R1) that will be sending the SIA-Query must be able to receive the UPDATE message poisoning the route from the successor of a route with no feasible successors (let’s call it R2)
- This router must be able to send a regular non-SIA query to another router (let’s call it R3) and receive an ACK back for that query message
- R3 must be able to send the ACK back, but NOT the regular non-SIA reply
- R1 must be able to send the SIA-Query to R3 and either receive an SIA reply (thereby keeping the neighborship alive and causing R3 to propagate an SIA query to its neighbors further downstream) or not (causing R1 to kill its neighborship with R3)
While some of these requirements don’t sound too hard to meet, the devil is in the details: you need to be able to send an ACK back, but unable to send either a reply or an SIA-reply.
This is also why you don’t see SIA that often, even in real EIGRP deployments. It’s a really niche edge case feature that really only exists to deal with intermittent traffic loss (e.g., while running EIGRP over lossy WAN links.) Think about it: how often are all of the stars going to line up WHILE your neighborship stays alive because hello messages are somehow still flowing? That’s not to say it never happens, but it definitely isn’t the norm.
So, to answer the question above - if this person has found a way to reliably lab how SIA works (hint: they didn’t), that definitely makes for a more interesting read than the news!
What Was This User’s Issue?
Oh yeah, getting back to story time hour! Pick up your popcorn buckets again!
The way that this user decided to lab SIA queries is with this topology:
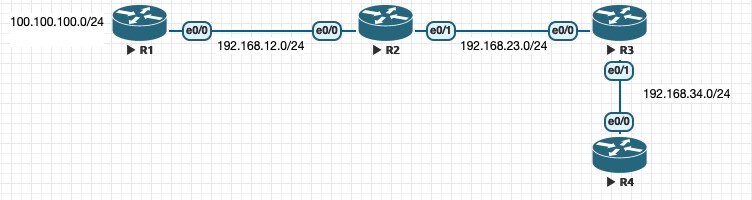
Figure 1: Their lab topology
Specifically, they applied a deny ip any any ACL inbound on R3’s Ethernet0/1 interface, thereby blocking all EIGRP traffic coming from R4, including any reply/ACK messages. Of course, to make this work, they also had to boost the living s*** out of the holdtime.
While debugging the SIA query messages, they found that the SIA queries were being supposedly “sent” to the neighbor. However, the output didn’t say sending - only enqueuing. None of the packet counters or packet captures revealed a SIA query message being sent onto the link. Despite that, the topology output (show ip eigrp topology) still showed an SIA query being sent out.
Interestingly enough, R4 was still being declared down after the 180 second timer. So, we have a case of a magic, disappearing SIA query that still somehow…does its job and kills the neighborship?
*audience gasps* IS MAGIC REAL???!?!?!?!
I sure hope so! In this case though, it’s not magic (shocker, right?)
This is when I have to break the news to you…make sure you’re seated! takes a deep breath
This post isn’t really going to be about SIA.
Now, hold on, before you pull out your pitchforks: why go into all of that detail about the backstory? Well, this story gives us a really interesting opportunity to discuss the cause behind the “disappearing” SIA-query message. Why is EIGRP basically lying to our faces by saying the SIA query was sent even if we can prove it hasn’t?
The culprit, as we’ll see, is the EIGRP interface queue and the separation that it creates between the various components of EIGRP!
EIGRP Interface Queue
Reliable Transport Protocol (RTP)
Within EIGRP lives another protocol known as the Reliable Transport Protocol (RTP). This is the EIGRP sub-protocol that handles reliably transported messages (gee, impossible to tell from the name, I know!)
RTP exists to accomplish two goals:
- Ensure that the remote router receives all reliably transported messages by requiring that the remote router sends an ACK back
- Ensure that those messages are sequenced properly to avoid out-of-order transmission/receipt
This is akin to how other reliable protocols, such as TCP, work.
These messages include pretty much everything but the hello message. UPDATE, QUERY (including SIA-Query), and REPLY (including SIA-Reply) messages are all reliably transported.
In RTP, these ACKs take the form of hello messages, since they are the only unacknowledged packet type in EIGRP. All reliably transported messages contain a sequence number. A hello message that is to be used as an acknowledgement contains this sequence number in its acknowledgement field, indicating that the hello message is intended to acknowledge the packet with that sequence number.
You can see this in the following packet capture. Simple enough! Figure 2: Update message containing sequence number 57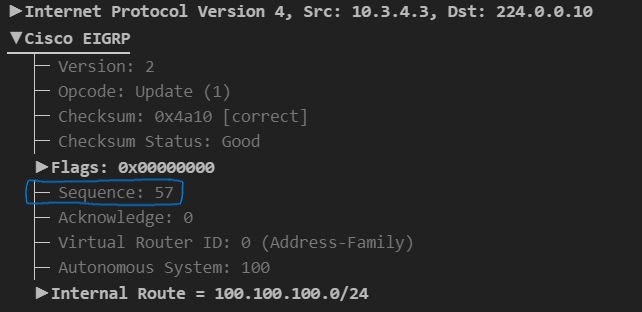
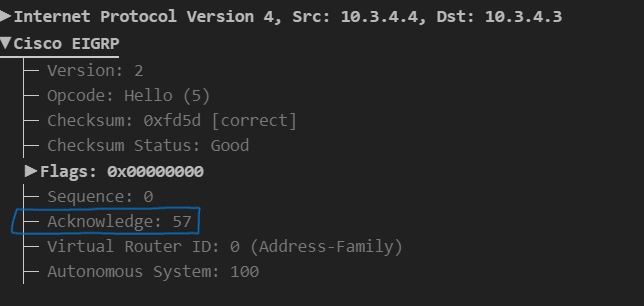
Figure 3: Hello message sent as an ACKnowledgement of sequence number 57
The Queue
EIGRP is a very complex protocol. As such, different parts of EIGRP handle different functions - sometimes the left hand doesn’t know what the right hand is doing! Let’s do a little bit of role-play, shall we?
Let’s say you are the part of EIGRP that manages the EIGRP topology and you have a routing update to announce. You spend some precious energy crafting that UPDATE packet. Now, you need to send it out. Since UPDATE messages are subject to RTP transport, you know that you need to properly sequence the UPDATE message amongst the other RTP-transported messages being sent out by EIGRP (potentially by other parts of EIGRP that you’ll need to coordinate with!) You also need to wait for the ACK to come back and resend the message if that ACK never comes back.
But there’s a problem - you have some other work to get back to! There’s a thousand more routes you need to handle, after all! You can’t be spending all of your time just babysitting this one UPDATE message!
The solution to this? The EIGRP queue! Instead of needing to handle sending out the UPDATE message, EIGRP gives itself the ability to send messages destined for a particular interface into that interface’s queue. RTP then services this queue. This has a number of advantages:
- RTP has one place to look to find all of the messages that currently need to be sent out of a given interface
- The EIGRP components sending those messages don’t need to sit there and wait around for acknowledgements, since RTP does all of that. Once it sends the message to the queue, from the perspective of that EIGRP component, the job of sending that message is done!
RTP-transported messages that are in the queue are only removed when the device receives an ACK back for that specific sequence number. Additionally, because sequencing is important, the queue is first-in-first-out (FIFO) - if another message comes into the queue while another is in front of it waiting on an ACK, that other message can go…let’s use the relatively respectful phrase “pound sand!”
There’s an important distinction to make between this queue and the queue we talk about in QoS - this is NOT the official forwarding queue. Rather, this “intermediate” queue allows EIGRP to keep track of the sequencing order of the messages and what messages are still awaiting acknowledgement. The EIGRP interface queue feeds into the main interface queue that is actually used to shoot messages out of the device.
It Works, Until It Doesn’t!
Under normal circumstances, this queue isn’t worth thinking about. ACKs fly in so quickly, messages are never sitting in queue for all that long. When you run a show ip eigrp neighbors, the Q count/Qcnt (the indicator of how many messages are sitting in queue) will almost certainly be zero, unless you are extraordinarily lucky and manage to catch a packet for the milliseconds that it is sitting waiting for an ACK.
If your ACKs are getting lost to the wind though, the queue can quickly become a problem! You’ll begin to get more messages in the queue, and your Q cnt will be…decidedly not zero.
Beyond messages beginning to pile up in the queue, there’s also the issue of the ignorance of the other parts of EIGRP. Remember, other parts of EIGRP take the “I sent it to the queue, it’s no longer my problem” approach to interacting with the queue.
This means that if a message ever gets stuck in the queue due to a loss of ACKs, not only will the queue halt service, but the other parts of EIGRP won’t be aware that there’s any issue with the queue or the stuck message(s) at all!
Labbing It Up
Building the Lab
To see this in action for ourselves, let’s go ahead and recreate their lab in our CML environment to reproduce the behaviors they saw!

Figure 4: Here is the topology diagram of the lab!
All interfaces on all devices have EIGRP enabled under AS 100:
router eigrp 100
network 0.0.0.0
As we saw in the original lab, we’ll mostly be focused on R3 and R4, as well as the 100.100.100.0/24 route originated by R1.
Let’s go ahead and configure the inbound ACL on R3 to deny all traffic coming from R4. We’ll also configure 10,000 seconds as a hold-time to ensure that the neighborship doesn’t walk off a cliff immediately!
NOTE: Remember, EIGRP’s hold time works the opposite of what intuition would tell you. Your locally configured hold-time is what you tell your neighbor to use. As such, to tell R3 not to freak out about the missing hello packets, we need to configure the hold time on R4’s interface facing R3.
R4(config)#interface GigabitEthernet1
R4(config-int)#ip hold-time eigrp 100 10000
R3(config)#access-list 101 deny ip any any
R3(config)#interface GigabitEthernet2
R3(config-int)#ip access-group 101 in
Let’s go ahead and verify the neighborship between those two routers.
R3#sho ip eigrp nei detail 10.3.4.4
EIGRP-IPv4 Neighbors for AS(100)
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
1 10.3.4.4 Gi2 9997 00:16:37 8 225 0 3
Version 28.0/2.0, Retrans: 4, Retries: 0, Prefixes: 1
Topology-ids from peer - 0
Topologies advertised to peer: base
Max Nbrs: 0, Current Nbrs: 0
Great! The neighborship is up and everything looks great. Let’s also verify that R3 is learning about the route to 100.100.100.0/24:
R3#sh ip eigrp top 100.100.100.0/24
EIGRP-IPv4 Topology Entry for AS(100)/ID(3.3.3.3) for 100.100.100.0/24
State is Passive, Query origin flag is 1, 1 Successor(s), FD is 131072
Descriptor Blocks:
10.2.3.2 (GigabitEthernet1), from 10.2.3.2, Send flag is 0x0
Composite metric is (131072/130816), route is Internal
Vector metric:
Minimum bandwidth is 1000000 Kbit
Total delay is 5020 microseconds
Reliability is 255/255
Load is 1/255
Minimum MTU is 1500
Hop count is 2
Originating router is 100.100.100.100
What Happened?
Wrapping back around to what we talked about earlier, the key is that from the perspective of the EIGRP component that originated that message, the message was sent, even if it’s stuck in queue!
Now, we’ll go ahead and shut down the Loopback1 interface on R1, which will cause R1 to poison the associated 100.100.100.0/24 route:
R1(config)#interface Loopback1
R1(config-int)#shutdown
After R1’s poison update reaches R3 through R2, R3 loses its only available successor/feasible successor to the route, so the route goes active.
R3#sh ip eigrp top 100.100.100.0/24
EIGRP-IPv4 Topology Entry for AS(100)/ID(3.3.3.3) for 100.100.100.0/24
State is Active, Query origin flag is 3, 1 Successor(s), FD is Infinity
Waiting for 1 replies
Descriptor Blocks:
10.2.3.2 (GigabitEthernet1), from 10.2.3.2, Send flag is 0x0
Composite metric is (Infinity/Infinity), route is Internal
Vector metric:
Minimum bandwidth is 4294967295 Kbit
Total delay is 281474976 microseconds
Reliability is 204/255
Load is 0/255
Minimum MTU is 0
Hop count is 255
Originating router is 100.100.100.100
At this point, the standard query process ensues. R3 tries to find another available successor by using all EIGRP-enabled interfaces, including the GigabitEthernet2 interface facing R4, to blast out queries.
R3 queues and sends a query to R4, which should be sending an ACK back to push the query out of queue. It would be a dang shame if we had something like, I dunno, an inbound ACL facing R4 denying all traffic on R3 that shoots that ACK out of existence and keeps the query in the queue infinitely…
R3#sho ip access-list int g2
Extended IP access list 101
10 deny ip any any
…
GOSH DARN IT.
We can see this by debugging the EIGRP packets we’re interested in, including queries. Notice that we are queuing up query messages! Pun not intended, by the way, but I’m proud of that one!
R3#debug eigrp packets ack query reply siaquery siareply
(QUERY, REPLY, ACK, SIAQUERY, SIAREPLY)
EIGRP Packet debugging is on
R3#
*Oct 4 05:13:08.765: EIGRP: Enqueueing QUERY on Gi2 - paklen 0 tid 0 iidbQ un/rely 0/1 serno 20-20
*Oct 4 05:13:08.767: EIGRP: Sending QUERY on Gi2 - paklen 44 tid 0
*Oct 4 05:13:08.767: AS 100, Flags 0x0:(NULL), Seq 25/0 interfaceQ 0/0 iidbQ un/rely 0/0 serno 20-20
*Oct 4 05:13:11.340: EIGRP: Sending QUERY on Gi2 - paklen 44 nbr 10.3.4.4, retry 1, RTO 3861 tid 0
*Oct 4 05:13:11.341: AS 100, Flags 0x0:(NULL), Seq 25/10 interfaceQ 0/0 iidbQ un/rely 0/0 peerQ un/rely 0/1 serno 20-20
*Oct 4 05:13:15.203: EIGRP: Sending QUERY on Gi2 - paklen 44 nbr 10.3.4.4, retry 2, RTO 5000 tid 0
*Oct 4 05:13:15.203: AS 100, Flags 0x0:(NULL), Seq 25/10 interfaceQ 0/0 iidbQ un/rely 0/0 peerQ un/rely 0/1 serno 20-20
*Oct 4 05:13:20.205: EIGRP: Sending QUERY on Gi2 - paklen 44 nbr 10.3.4.4, retry 3, RTO 5000 tid 0
*Oct 4 05:13:20.205: AS 100, Flags 0x0:(NULL), Seq 25/10 interfaceQ 0/0 iidbQ un/rely 0/0 peerQ un/rely 0/1 serno 20-20
As we send them out, notice that R3 isn’t receiving any ACKs back! The ACK (and the reply message!) from R4 is coming through, but our ACL is doing its job! Darn you, ACL…

Figure 5: Packet capture showing the ACK and reply sent from R4 in response to the query from R3
RTP doesn’t like that! So, every time the retransmission timeout (RTO) interval passes, it will re-send the query. This also means that the query message is stuck in the EIGRP queue for the GigabitEthernet2 interface.
We can also confirm this by looking at the neighbor details. Notice that the Q count is not zero (indicating that there are messages stuck in the queue) and that the query message we saw in the debug is listed!
R3#sho ip eigrp nei det 10.3.4.4
EIGRP-IPv4 Neighbors for AS(100)
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
1 10.3.4.4 Gi2 9930 00:18:11 8 5000 1 3
Version 28.0/2.0, Retrans: 22, Retries: 18, Prefixes: 1
Topology-ids from peer - 0
Topologies advertised to peer: base
QUERY seq 9 ser 9-9 Len 44 Sent 62910 Sequenced
Max Nbrs: 0, Current Nbrs: 0
Of course, the part of EIGRP sending out the query for the active route has no clue the query didn’t go out properly. That is why the EIGRP topology output simply states that the query has been sent!
R3#sho ip eigrp top active
EIGRP-IPv4 Topology Table for AS(100)/ID(3.3.3.3)
Codes: P - Passive, A - Active, U - Update, Q - Query, R - Reply,
r - reply Status, s - sia Status
A 100.100.100.0/24, 1 successors, FD is Infinity, Q
1 replies, active 00:00:33, query-origin: Successor Origin
via 10.2.3.2 (Infinity/Infinity), GigabitEthernet1
Remaining replies:
via 10.3.4.4, r, GigabitEthernet2
The r (via 10.3.4.4, r, GigabitEthernet2) means that, from the perspective of the EIGRP topology table, it has been sent.

Figure 6: Table showing the meaning of the s and r codes in the EIGRP topology table
Source: Cisco IOS IP Routing: EIGRP Command Reference
Of course, we know this isn’t true! However, the part of EIGRP managing the topology just says:
Hey, I sent it to the queue, that must mean R4 got it!
As a result, when R3 doesn’t see a reply in 90 seconds, its reaction is not:
Hmm, R4 might not have gotten that query message.
Rather, it’s:
That. Gosh. Darn. Jerk. How dare you not respond to my query, even though you obviously got it! You wanna act too cool for school? Here, take this SIA-Query to the face!!!
So, after a little while of waiting, R3 gets fed up with waiting for the query and decides to send an SIA query! This, of course, gets promptly serviced by RTP because the front of the queue is empty-
stares at the query message taking up space in the front of the queue
Crap.
Notice in our debug output that, despite queuing the SIA-Query up, it continues to send the normal query out, due to its place ahead of the SIA query in the queue.
*Oct 4 05:14:39.747: EIGRP: Enqueueing SIAQUERY on Gi2 - paklen 0 nbr 10.3.4.4 tid 0 iidbQ un/rely 0/1 peerQ un/rely 0/1 serno 21-21
*Oct 4 05:14:40.263: EIGRP: Sending QUERY on Gi2 - paklen 44 nbr 10.3.4.4, retry 19, RTO 5000 tid 0
*Oct 4 05:14:40.268: AS 100, Flags 0x0:(NULL), Seq 25/10 interfaceQ 0/0 iidbQ un/rely 0/0 peerQ un/rely 0/2 serno 20-20
*Oct 4 05:14:45.271: EIGRP: Sending QUERY on Gi2 - paklen 44 nbr 10.3.4.4, retry 20, RTO 5000 tid 0
*Oct 4 05:14:45.272: AS 100, Flags 0x0:(NULL), Seq 25/10 interfaceQ 0/0 iidbQ un/rely 0/0 peerQ un/rely 0/2 serno 20-20
We can confirm this in the packet capture:

Figure 7: Packet capture after SIA query queued, showing that the normal query is still being sent out
As such, both messages are stuck in the queue. We can confirm this, once again, by looking at our neighbor details. Notice the lack of a sent counter for the SIAQUERY, indicating that it hasn’t ever been sent out of the interface.
R3#sho ip eigrp nei det 10.3.4.4
EIGRP-IPv4 Neighbors for AS(100)
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
1 10.3.4.4 Gi2 9834 00:04:46 429 5000 2 10
Version 28.0/2.0, Retrans: 50, Retries: 32, Prefixes: 1
Topology-ids from peer - 0
Topologies advertised to peer: base
QUERY seq 25 ser 20-20 Len 44 Sent 157107 Sequenced
SIAQUERY seq 27 ser 21-21 Sequenced
Max Nbrs: 0, Current Nbrs: 0
And, of course, the same story repeats with the SIA-Query. The part of EIGRP sending the SIA-Query thinks that it has been sent, because it got queued. That is why EIGRP sets the SIA status flag in the topology table entry for the route.
R3#sho ip eigrp top active
EIGRP-IPv4 Topology Table for AS(100)/ID(3.3.3.3)
Codes: P - Passive, A - Active, U - Update, Q - Query, R - Reply,
r - reply Status, s - sia Status
A 100.100.100.0/24, 1 successors, FD is Infinity, Qqr
1 replies, active 00:02:10, query-origin: Successor Origin, retries(1)
via 10.2.3.2 (Infinity/Infinity), GigabitEthernet1, serno 36
via 10.3.4.4 (Infinity/Infinity), rs, q, GigabitEthernet2, serno 35, anchored
Who cares if it hasn’t actually been sent - minor details!
After another 90 seconds (180 seconds total on the original active timer) with neither a reply nor an SIA-reply from R4, the neighborship dies a quick death as EIGRP deems it stuck in active.
R3#
*Oct 4 05:16:10.323: %DUAL-3-SIA: Route 100.100.100.0/24 stuck-in-active state in base 100. Cleaning up
*Oct 4 05:16:10.326: %DUAL-5-NBRCHANGE: EIGRP-IPv4 100: Neighbor 10.3.4.4 (GigabitEthernet2) is down: stuck in active
Conclusion
This was a fun opportunity to talk about how queuing in EIGRP works, but it can cause problems if you aren’t vigilant of it.
The lesson to be learnt here is that there is immense value in understanding how the technologies we work with actually work, even if the details seem small and insignificant.
It’s pretty hard to blame you if you looked at the output telling you “yeah, I sent the SIA-query to the other device” and thought “oh, yeah, it sent the SIA-query to the other device.”
That being said, if you know to interpret it instead as “oh, yeah, it queued the SIA-query,” you end up understanding the situation more clearly. While this is a fairly low-stakes example in a lab, the same principle applies elsewhere!