Introduction
Once in a while, I like posting challenges in some of the technical Discord communities I participate in! I find that it’s fun for me to write them and it ends up being informative for a lot of people!
Just like a dunk tank at the carnival, it’s fun for everyone! People have fun throwing the balls and the person in the tank has fun not being dunked…because, let’s be real, how many people are actually gonna hit their shot?
Anyway, I figured it’s time to share these challenges and talk about their solutions on my blog as well! This is a fun first one!
The Challenge
You have the following topology:

Figure 1: Main topology
A basic MPLS L3VPN service is configured using BGP VPNv4 between the two PEs. BGP is used as the PE-CE routing protocol, with CE1 and CE2 hosting two customer networks behind them that are advertised into BGP VPNv4 within VRF C1. The baseline is that the two networks can ping each other:
H2#ping 11.0.0.1 so 12.0.0.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 11.0.0.1, timeout is 2 seconds:
Packet sent with a source address of 12.0.0.1
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/5/6 ms
H2#traceroute 11.0.0.1 so 12.0.0.1
Type escape sequence to abort.
Tracing the route to 11.0.0.1
VRF info: (vrf in name/id, vrf out name/id)
1 10.4.12.4 1 msec 2 msec 1 msec
2 10.3.4.3 [MPLS: Labels 3001/1003 Exp 0] 7 msec 6 msec 5 msec
3 10.2.3.2 [MPLS: Labels 2000/1003 Exp 0] 69 msec 9 msec 6 msec
4 10.1.11.1 [MPLS: Label 1003 Exp 0] 9 msec 6 msec 7 msec
5 10.1.11.11 5 msec * 6 msec
The MPLS forwarding table from PE1 is shown below:
PE1#sho mpls for
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
1000 Pop Label 2.2.2.2/32 0 Gi1.12 10.1.2.2
1001 2001 3.3.3.3/32 0 Gi1.12 10.1.2.2
1002 2002 4.4.4.4/32 0 Gi1.12 10.1.2.2
1003 No Label 11.0.0.0/24[V] 4326 Gi1.111 10.1.11.11
You want to test a connectivity failure over the MPLS core. To do this, you apply the following route to the egress PE (PE1 in the PE2 -> PE1 flow):
PE1(config)#ip route 11.0.0.1 255.255.255.255 null0
After applying this configuration, however, the 11.0.0.1 host is still reachable:
H2#ping 11.0.0.1 so 12.0.0.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 11.0.0.1, timeout is 2 seconds:
Packet sent with a source address of 12.0.0.1
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/4/6 ms
(a) Why is this occurring?
(b) What must be done in order to block the traffic using the null route shown above? The block must occur as a direct result of the presence of that route (i.e., the sole removal/addition of the route shown above should be all that is necessary to fix/break connectivity respectively.) Note that you cannot change or add any static routes. You also may not disable MPLS in any way. In the end configuration, MPLS must be configured such that the composition of the label stack is not meaningfully different (i.e., a double label stack with transport/VPN labels must be present up until the penultimate hop, at which point the LDP transport label is popped off and only the VPN label is sent to the egress PE, which should pop it off and send an unlabeled packet to the CE.)
This challenge can be very, very tricky! It is a great test that ties together a bunch of your fundamental MPLS knowledge.
Without further ado, let’s dive into the solution.
Let’s Forget About MPLS for a Minute
MPLS makes a lot of things more complicated, which is ironic seeing as a label is seemingly just a number! Regardless, in order to see what we intend to happen, let’s remove MPLS from the equation and focus on a much simpler topology:
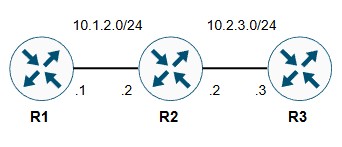
Figure 2: Simplified topology
OSPF is enabled between each of these routers. As such, all three routers will be aware of both directly connected links. Let’s suppose that R3 wants to ping the IP address of R1’s interface:
R3#ping 10.1.2.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.1.2.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 5/6/8 ms
R3#traceroute 10.1.2.1
Type escape sequence to abort.
Tracing the route to 10.1.2.1
VRF info: (vrf in name/id, vrf out name/id)
1 10.2.3.2 2 msec 2 msec 2 msec
2 10.1.2.1 3 msec * 4 msec
Awesome, it works! I mean, it is just simple OSPF with two directly connected networks, but still - let’s pat ourselves on the back for a moment!
Evil scientist glasses on, people - it’s time to break sh*t.
R2(config)#ip route 10.1.2.1 255.255.255.255 null0
And…based on a show ip route, it looks like that route was successfully installed.
R2#sho ip route | b Gate
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 5 subnets, 2 masks
C 10.1.2.0/24 is directly connected, GigabitEthernet1
S 10.1.2.1/32 is directly connected, Null0
L 10.1.2.2/32 is directly connected, GigabitEthernet1
C 10.2.3.0/24 is directly connected, GigabitEthernet2
L 10.2.3.2/32 is directly connected, GigabitEthernet2
R2#sho ip route 10.1.2.1 255.255.255.255
Routing entry for 10.1.2.1/32
Known via "static", distance 1, metric 0 (connected)
Routing Descriptor Blocks:
* directly connected, via Null0
Route metric is 0, traffic share count is 1
Let’s break this route down. We’re adding a static route to R2 pointing to the /32 of the IP address on R1 that we are pinging. By the way - the fact that it’s a static route is completely irrelevant to this example. It could be an OSPF route, BGP route, or magic route! This tells us that administrative distance is not involved in this decision.
That makes sense, too - remember that AD only kicks in if two routes point to the exact same prefix. In this case, we’re comparing routes to 10.1.2.0/24 (the connected route) and 10.1.2.1/32 (this static route). As such, longest match is solely responsible for our forwarding decision. Of course, /32 routes are the reigning champs of the longest match game - nothing’s beaten it!
On top of that, this ain’t no ordinary static route! This is the static route of nightmares - instead of forwarding the packet onto its destination, it goes out this Null0 interface and into the void, where the rest of the misfit packets live! In slightly less scary terms, anything sent to Null0 is immediately dropped.
Combining all of that - when R3 sends packets to R1’s 10.1.2.1 IP address, it is routed to R2. R2 performs a longest match lookup to determine how to handle this packet. However, instead of finding a /24 connected route that is excited and ready to send that packet onto its destination, R2 finds a /32 static route that is…less willing to do that.
R3#ping 10.1.2.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.1.2.1, timeout is 2 seconds:
U.U.U
Success rate is 0 percent (0/5)
The result? Ping go bye-bye!
Et tu, MPLS?
You saw that our idea of using a null0 static route to reject the traffic went exactly to plan when dealing with regular IP forwarding! However, you also saw that MPLS wasn’t willing to play along! Even with the null0 static route in place on the egress PE (i.e., the PE directly connected to our 11.0.0.1 destination, PE1), the pings still went through!
Initially, you might think that this makes no sense! After all:
- The LDP transport label is fully popped off (due to PHP) by the time the packet reaches the egress PE. It’s just one VPN label and one fantastic IP header!
- The VPN label just serves to tell the egress PE what VRF to push the packet into
- The PE still relies on the normal IP routing table in order to route the traffic out of the PE-CE circuit
If everything I just said is correct (which it would seem to be), there’s no reason that this should behave any differently than the regular IP forwarding example.
So, as you probably figured, at least one of the things I said has to be wrong! Let’s analyze each point:
- The LDP transport label is fully popped off (due to PHP) by the time the packet reaches the egress PE. It’s just one VPN label and one fantastic IP header!
Well, if we look at our traceroute, we’ll see proof of this point!
H2#traceroute 11.0.0.1 so 12.0.0.1
Type escape sequence to abort.
Tracing the route to 11.0.0.1
VRF info: (vrf in name/id, vrf out name/id)
1 10.4.12.4 1 msec 2 msec 1 msec
2 10.3.4.3 [MPLS: Labels 3001/1003 Exp 0] 7 msec 6 msec 5 msec
3 10.2.3.2 [MPLS: Labels 2000/1003 Exp 0] 69 msec 9 msec 6 msec
4 10.1.11.1 [MPLS: Label 1003 Exp 0] 9 msec 6 msec 7 msec
5 10.1.11.11 5 msec * 6 msec
When we get to PE1, it’s just our VPN label 1003, with the IP header right below it. This can’t be wrong.
- The VPN label just serves to tell the egress PE what VRF to push the packet into
It is certainly true that VPN labels tell the egress PE about the destination VRF. Take the example of the 1003 label seen above. We can see that the LFIB entry for this label explicitly references the C1 VRF in the VPN route row:
PE1#sho mpls forwarding-table label 1003 detail
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
1003 No Label 11.0.0.0/24[V] 4916 Gi1.111 10.1.11.11
MAC/Encaps=18/18, MRU=1504, Label Stack{}
AABBCC000700525400F6A9178100006F0800
VPN route: C1
No output feature configured
However, notice that the LFIB entry for this label also indicates the following details:
- Prefix (11.0.0.0/24)
- Outgoing interface (GigabitEthernet1.111)
- Next hop (10.1.11.11)
Hmm…that sounds familiar. Let’s keep that in our minds for a moment.
- The PE still relies on the normal IP routing table in order to route the traffic out of the PE-CE circuit
Let’s think about this for a second and look at the normal IP CEF forwarding entry for the 11.0.0.0/24 network.
PE1#sho ip cef vrf C1 11.0.0.0/24
11.0.0.0/24
nexthop 10.1.11.11 GigabitEthernet1.111
Notice that we have the:
- Prefix (11.0.0.0/24)
- Outgoing interface (GigabitEthernet1.111)
- Next hop (10.1.11.11)
Sound familiar?
By taking the extra step of looking up the 11.0.0.0/24 route in the normal IP routing table and forwarding table (CEF FIB), we get the exact same information that we saw right from the get-go in the LFIB.
Knowing that, why would we ever take the extra time to look up the route in the regular IP FIB when we can just use the LFIB entry to figure out how to forward the packet to our destination?
The designers of MPLS thought of that exact point! That’s why we don’t rely on the normal IP routing table to route the traffic to the CE. The VPN label tells us more than just the egress VRF - it also gives us everything we need to send the packet to its destination. All PE1 needs to do is find the destination MAC address associated with the next hop (through ARP) and send the completed frame out of the listed outgoing interface.
One Part of the Puzzle Solved!
We’ve just made the revelation that we use the LFIB entry for the VPN label on PE1 to route the traffic towards the 11.0.0.1 destination. That helps us answer part (a) of this challenge - why is the null route having no effect?
It’s simple! There’s no label generated for the /32 static route (because it’s not advertised into BGP VPNv4, which is what generates the VPN labels), so there’s no entry for it in the LFIB. Since we are relying on the LFIB and not the regular IP FIB to forward the traffic, the null route is not considered by PE1. The entry for the /24 directly connected route remains the best match in the LFIB. Consequently, PE1 continues to send the traffic directly to the 11.0.0.1 IP address, in spite of the null route.
Drat! I hate when my evil plans are foiled by…completely logical and reasonable choices by the designers of MPLS!
What, You Think I Go Down That Easily?
Of course, there is still part (b) in this challenge. Let me paraphrase part (b):
You think I care that MPLS doesn’t want me using this null route? Find a way to use it anyway!
Of course, the restrictions on that question stop you from doing the obvious, cheeky thing: disabling MPLS across the core and transforming this into a regular IP forwarding scenario. Nope - MPLS is here to stay! (Please do take that as a challenge to find a creative answer, if you can…muahahahah!)
Introducing Label Allocation Modes
We’ve established that the VPN label LFIB entries include egress forwarding information for the specific prefix. However, the question remains - why do they contain that information?
Answering that is crucial for understanding the rest of the solution. The answer lies in the fact that VPN labels, by default on Cisco platforms, are generated on a per-prefix basis. If we advertise multiple prefixes, every single prefix will get its own VPN label.
To demonstrate this point, I’ve advertised another network behind PE1 (11.0.1.0/24) into BGP VPNv4 and used an outbound route policy on the CE to set the next hop to a different value (10.1.11.111) than the other prefix.
PE1#sho mpls forwarding-table vrf C1
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
1003 No Label 11.0.0.0/24[V] 7748 Gi1.111 10.1.11.11
1005 No Label 11.0.1.0/24[V] 0 Gi1.111 10.1.11.111
Notice that a new local label (1005) entry was created in the LFIB for the new prefix. Additionally, the distinct forwarding information is represented as part of that LFIB entry.
The main benefit of the per-prefix model is that it is dead simple. Just as there is a 1:1 mapping between LDP labels and prefixes in the global routing table (by default), the same applies to VPN labels. As we’ve seen, this allows us to map direct forwarding instructions (outgoing interface/next hop) to the VPN label, despite differences in those values between different prefixes. Since the VPN labels are separated, there is no conflict!
The main drawback, of course, is that every time a customer advertises a new prefix, a label and a drop of your sanity goes with it! This creates a huge scalability problem. If we run out of labels, bad things happen.
As such, reducing the label allocation per customer has been a large push for MPLS operators for a long time! To this end, there are plenty of more efficient allocation modes that are more conservative in how they allocate labels.
PE1(config)#mpls label mode all-vrfs protocol all-afs ?
per-ce Per CE label
per-prefix Per prefix label (default)
per-vrf Per VRF label for entire VRF
vrf-conn-aggr Per VRF label for connected and BGP aggregates in VRF
vrf-conn-aggr is very niche and isn’t worth covering, so we’ll skip over it.
For the other two that we haven’t discussed yet:
- Per-CE - creates a single label for a group of prefixes that share the same next hop/outgoing interface
- Per-VRF - creates a single label for the entire VRF
In terms of the amount of labels conserved, per-prefix < per-CE < per-VRF.
Let’s take a look at per-CE first! We’ll set the command:
PE1(config)#mpls label mode all-vrfs protocol all-afs per-ce
This command sets the label allocation mode for all VRFs and both IPv4 and IPv6 to per-CE. Yes, this means that you can vary it for VRFs/AFs!
Let’s look at what’s changed in the LFIB! Notice that, instead of the label indicating the matching prefix, it simply indicates that the label corresponds to this particular next hop (10.1.11.11). That’s because a single next hop can map to multiple prefixes, so showing a prefix there would be fairly meaningless.
PE1#sho mpls for label 1006
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
1006 No Label nh-id(3) 0 Gi1.111 10.1.11.11
I removed the outbound route policy that forced the next hop to another value, so now the next hop for both prefixes is the same 10.1.11.11 next hop. As we see in the following output, both prefixes share the same label as a result!
PE1#sho bgp vpnv4 unic vrf C1 labels | i 10.1.11.11
11.0.0.0/24 10.1.11.11 1006/nolabel
11.0.1.0/24 10.1.11.11 1006/nolabel
Notice that this changes if we differentiate the next hops:
PE1#sho bgp vpnv4 unic vrf C1 labels | i 10.1.11.11
11.0.0.0/24 10.1.11.11 1006/nolabel
11.0.1.0/24 10.1.11.111 1004/nolabel
PE1#sho mpls for | i nh-id
1004 No Label nh-id(4) 0 Gi1.111 10.1.11.111
1006 No Label nh-id(3) 0 Gi1.111 10.1.11.11
However, it’s important to note that the per CE mode doesn’t change the forwarding behavior we discussed earlier. Just like per-prefix mode, the VPN labels in per-CE mode give us:
- the egress VRF
- outgoing interface
- next-hop
This information is populated into the LFIB, as the next hop and associated outgoing interface are known as a result of grouping prefixes by their next hop.
The only information that is now missing is the prefix. However, the prefix isn’t that important. Even in the per-prefix mode, we were label switching based on the VPN label. Since we’re not referencing the regular IP FIB, we don’t need IP addressing/prefix information to make a forwarding decision. PE1 just needs to know the VPN label and where to take the traffic!
Let’s now examine per-VRF mode! We’ll configure the following commands to remove the per-CE mode and replace it with the per-VRF mode:
PE1(config)#no mpls label mode all-vrfs protocol all-afs per-ce
PE1(config)#mpls label mode all-vrfs protocol all-afs per-vrf
Now, if we examine the LFIB:
PE1#sho mpls for vrf C1
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
1007 No Label IPv4 VRF[V] 0 aggregate/C1
Woah, woah, woah - hang on! Where’d the next hop information go? Where did the outgoing interface go?
PE1#sh ip int br | i aggregate/C1
PE1#
I don’t think aggregate/C1 is a valid interface!
Well, before we sound the emergency alarm and conclude that the aliens must have come to get us, let’s walk through what’s going on here!
Remember, per-VRF mode issues a single label for every prefix in the entire VRF, regardless of the next hop:
PE1#sho bgp vpnv4 unic vrf C1 labels | i 11
11.0.0.0/24 10.1.11.11 IPv4 VRF Aggr:1007/nolabel
11.0.1.0/24 10.1.11.111 IPv4 VRF Aggr:1007/nolabel
Despite the differing next hops, the VPN label is still 1007 for both prefixes!
Remember how the per-CE labels removed the prefix information from the LFIB entry, as it was meaningless with a label that included multiple prefixes? The same logic applies here, except with the addition of the next hop and, by association, outgoing interface! Since there are multiple next hops that could be included in this label, it doesn’t make sense to list a particular next hop and associated outgoing interface.
So, what information does this per-VRF VPN label give us?
- the egress VRF
- …and that’s it
…well, shoot.
Remember this bullet point?
- The VPN label just serves to tell the egress PE what VRF to push the packet into
In per-VRF mode, that is entirely correct! Without any kind of next-hop/outgoing interface information, there is no forwarding information provided by the VPN label whatsoever.
We can beg the router to give us more information all we want:
PE1#sho mpls for label 1007 det
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
1007 No Label IPv4 VRF[V] 0 aggregate/C1
MAC/Encaps=0/0, MRU=0, Label Stack{}
VPN route: C1
No output feature configured
Erm…there’s nothing there!
Without any forwarding information, we can’t pull the same trick of relying solely on the LFIB for routing labeled packets to their final destination as we did with per-CE and per-prefix labeling. We don’t know where to go!
You know what does include the forwarding information that we need, though?
PE1#sho ip cef vrf C1 11.0.0.0/24
11.0.0.0/24
nexthop 10.1.11.11 GigabitEthernet1.111
That’s right - our trusty old friend, the normal IP routing table and forwarding table!
But wait, that means…oh gosh.
- The PE still relies on the normal IP routing table in order to route the traffic out of the PE-CE circuit
This bullet point that we talked about earlier is also specifically true for per-VRF mode!
To recap - when we run a per-VRF label allocation mode, the VPN label only points to the egress VRF and provides no information regarding the outgoing interface and next hop. Since we lack the requisite forwarding information in the LFIB to label switch packets out to their destination, we need to cross-reference against the normal IP FIB to discover that information.
In other words, when a packet labeled with a per-VRF VPN label arrives at the PE:
- The PE processes the per-VRF VPN label and inserts that packet into the associated VRF. The VPN label is then popped off, since the LFIB entry specifies no egress label
- The normal rules of IP forwarding apply from here on out - the IP header is processed to discover the destination IP address, which is referenced against the IP FIB
It All Comes Full Circle!
Now that you understand the nuts and bolts of label allocation modes, it’s time to go back to part (b) of our challenge!
Recall that, under normal IP routing, the laws of longest match dictate that we choose the 11.0.0.1/32 static route to forward traffic to 11.0.0.1. Recall that, with MPLS, we saw that the normal IP routing table was ignored in favor of directly using the forwarding information included in the VPN label. As such, the router never had the opportunity to consider the static route, which was not in the LFIB.
The solution, then, is to force the router to reference the normal IP routing table when label switching the traffic. What better way to do that than to remove any forwarding information from the VPN label using that per-vrf thing that we just talked about? :D
Let’s do it! After applying the per-vrf configuration shown above, we can verify that it’s enabled using the following command:
PE1#sh vrf detail C1 | i per-vrf
VRF label allocation mode: per-vrf (Label 1007)
Let’s delete the static route to get a baseline for our ping working: PE1(config)#no ip route 11.0.0.1 255.255.255.255 null0
H2#ping 11.0.0.1 so 12.0.0.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 11.0.0.1, timeout is 2 seconds:
Packet sent with a source address of 12.0.0.1
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/5/6 ms
Awesome, just what we were expecting! Let’s re-add that route: PE1(config)#ip route 11.0.0.1 255.255.255.255 null0
H2#ping 11.0.0.1 so 12.0.0.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 11.0.0.1, timeout is 2 seconds:
Packet sent with a source address of 12.0.0.1
U.U.U
Success rate is 0 percent (0/5)
H2#tracer 11.0.0.1 so 12.0.0.1
Type escape sequence to abort.
Tracing the route to 11.0.0.1
VRF info: (vrf in name/id, vrf out name/id)
1 10.4.12.4 2 msec 1 msec 1 msec
2 10.3.4.3 [MPLS: Labels 3001/1007 Exp 0] 5 msec 5 msec 4 msec
3 10.2.3.2 [MPLS: Labels 2000/1007 Exp 0] 4 msec 4 msec 5 msec
4 10.1.11.1 9 msec 8 msec 8 msec
5 10.1.2.1 !H * !H
And bingo! The traffic continues to be tunneled in an MPLS LSP, using a double label stack containing the VPN label corresponding to the VRF. This continues until PE1 (10.1.11.1), which removes both labels and performs normal IP routing using the /32 null static route.
One interesting note - compared to the original traceroute output provided in the challenge, PE1 no longer reports a VPN label. That’s because the VPN label is popped off before PE1 considers generating the ICMP Time Expired error message.
Most importantly, though…to the affected packets: enjoy the void!
Conclusion
This is one example of the importance of understanding the fundamentals of complicated technologies, such as MPLS! While this challenge itself isn’t super commonly applicable in practice, there are a LOT of practical implementations for the forwarding behaviors we discussed today! For example, in the per-prefix/per-CE modes, the IP ToS byte isn’t processed - only the MPLS CoS/TC bits, which have less granularity than the ToS byte and the DSCP marking that it may contain. However, in the per-VRF mode, IP QoS is possible, due to the normal IP forwarding that occurs.
Beyond that, when you get into Juniper L3VPN, there is a very similar command in the VRF called vrf-table-label that often sparks a lot of ire and confusion. When you realize that the bulk of the functionality is just equivalent to the per-vrf option we talked about, how it behaves makes a lot more sense!
Until next time…more MPLS!